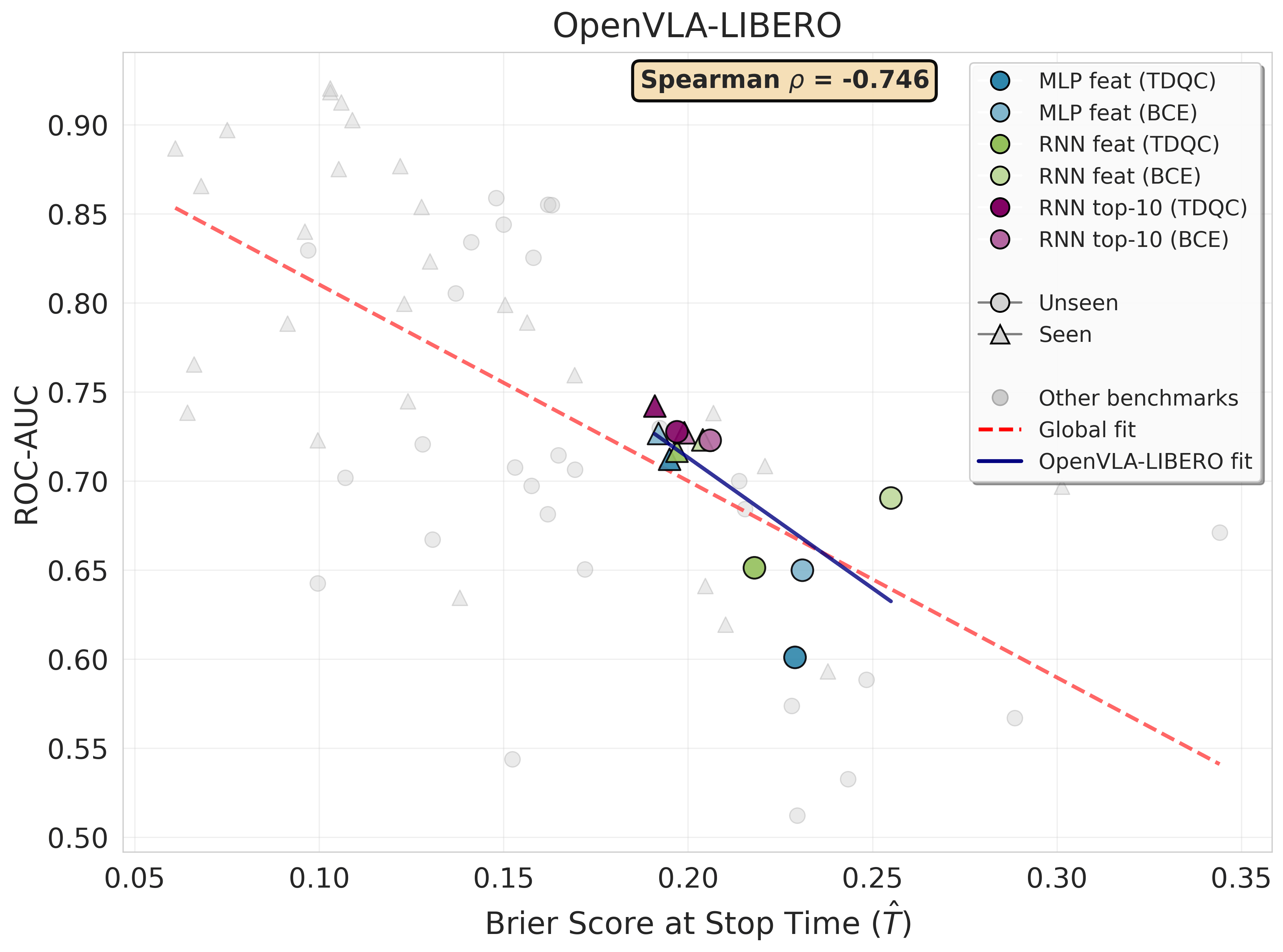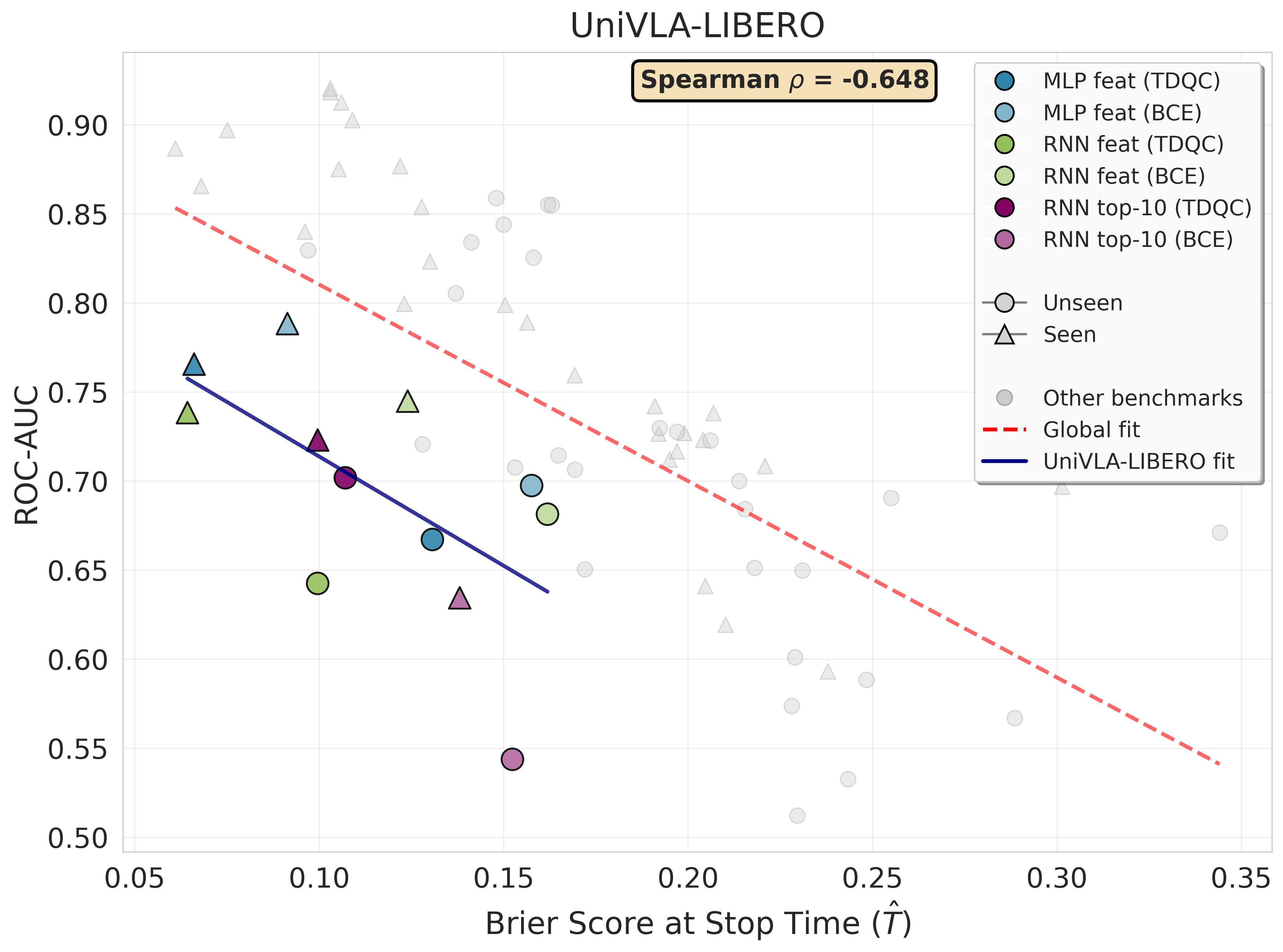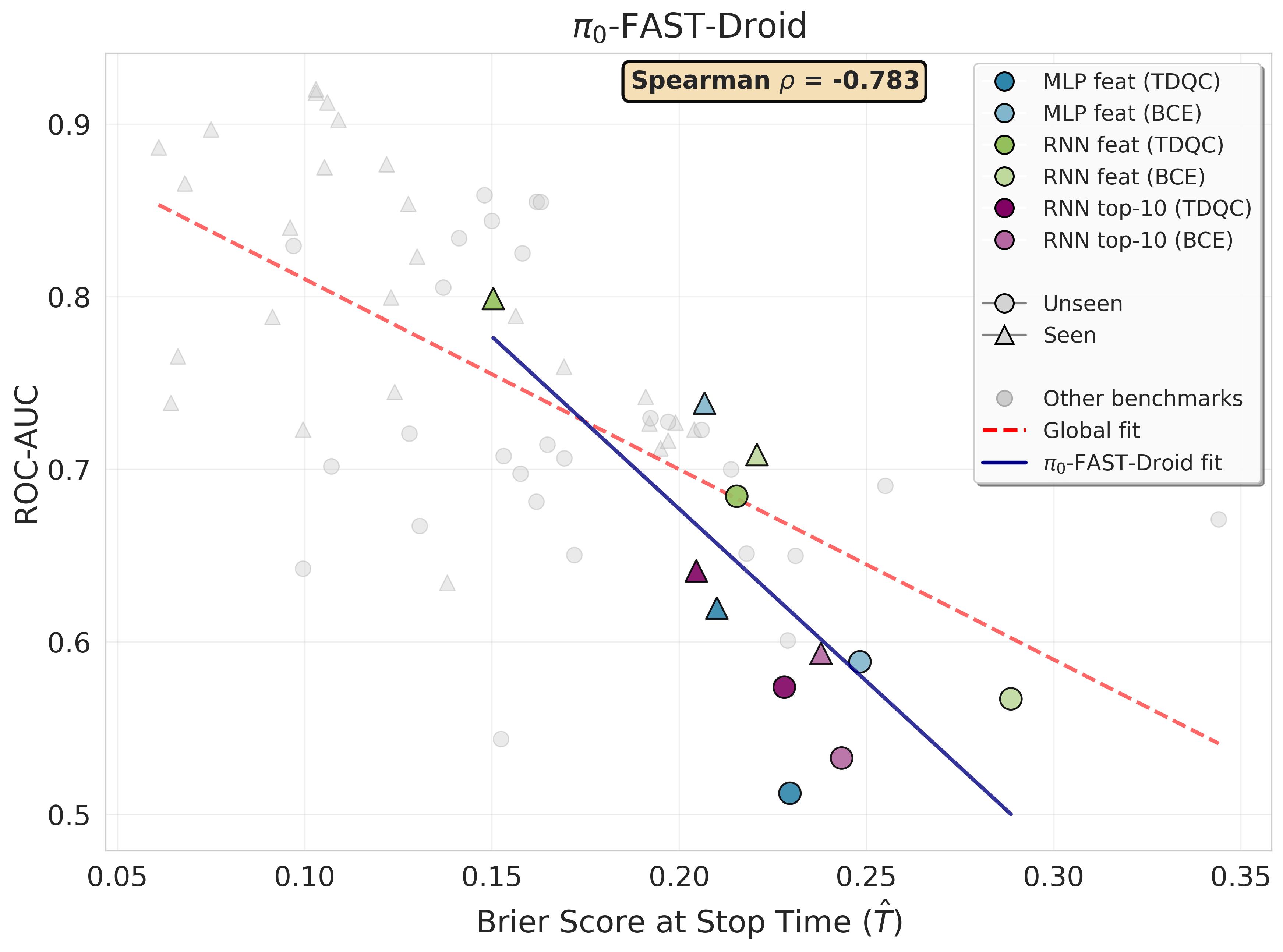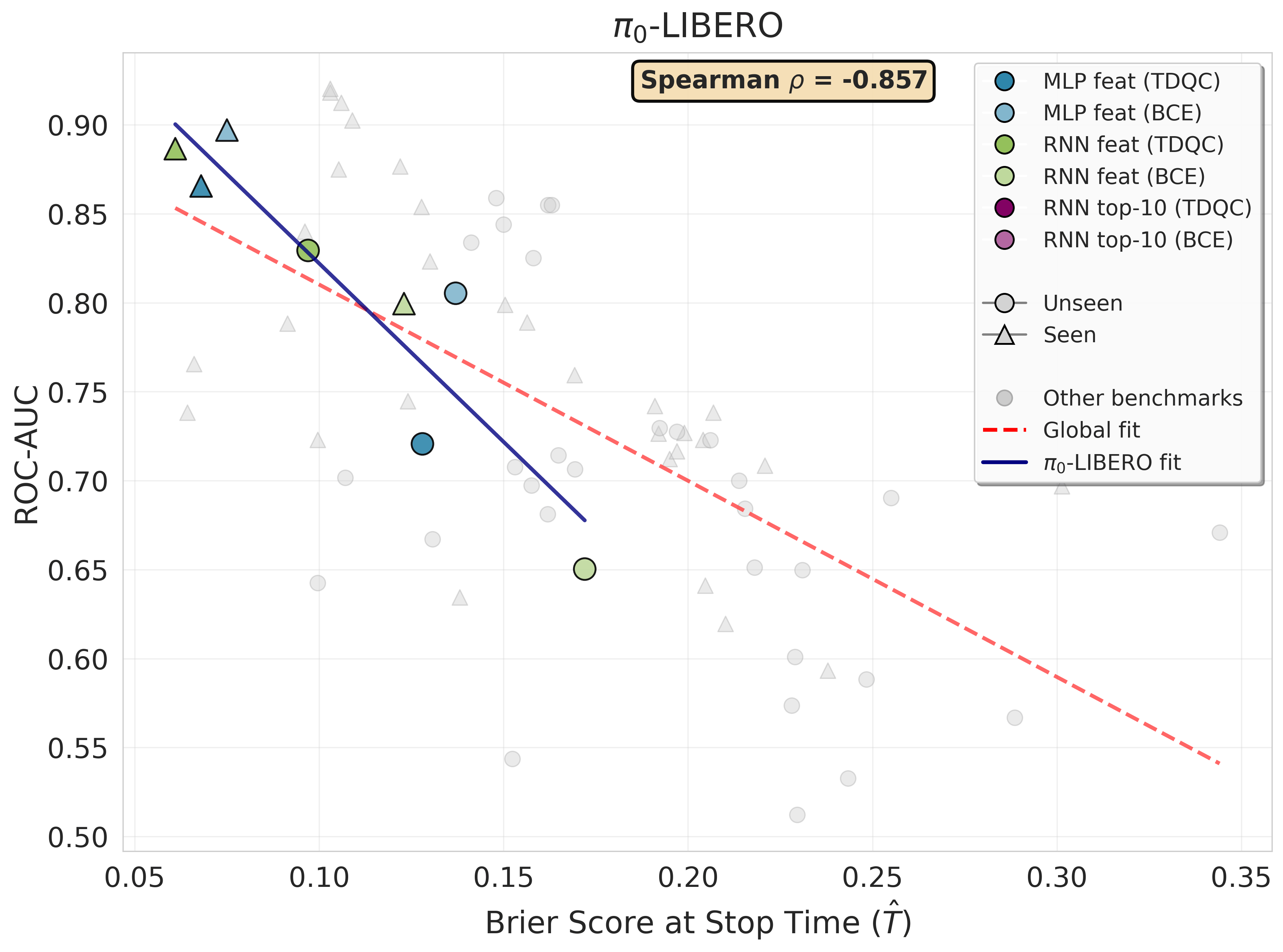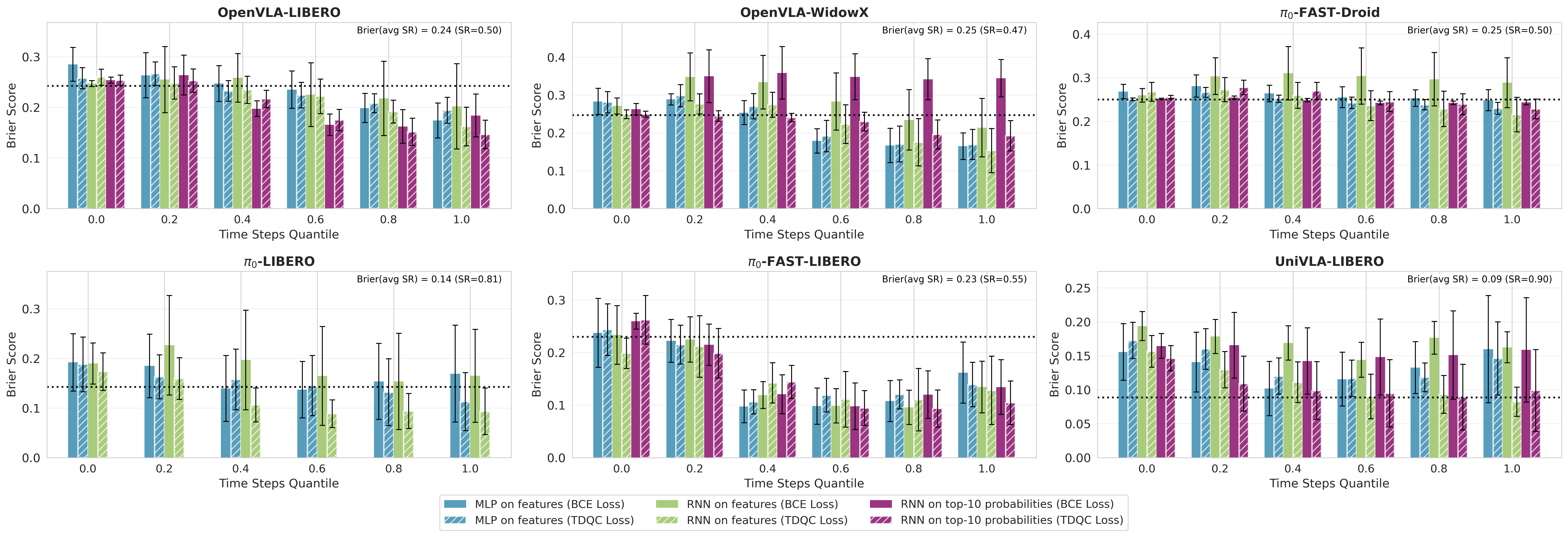
Figure 1 — Brier Score · Validation (Unseen Split)
Sequential Brier score (lower is better) on an unseen validation set averaged over 21 random seeds (train/validation task splits). To compare calibration across rollouts with different lengths, we report Brier score over time quantiles. Each subplot corresponds to a (VLA model, benchmark) pair. Success prediction methods are based on sequences of features or action probabilities. Across all settings, our TD-based methods consistently outperform conventional predictors trained with binary cross entropy (BCE). For \(\pi_0\) action probabilities are not directly interpretable, hence probability-based TDQC variants are not reported. The dotted horizontal line represents the Brier score of a constant predictor that consistently outputs the empirical mean success rate computed over the seen tasks (see Remark 4.2).